Lehrstuhl Wissenschaftliches Rechnen
GPU Computing: Efficient Implementation of Finite Difference Stencils
Several ways of tuning a model problem finite difference stencil computation are discussed. The combination of vectorisation and an interleaved data layout, cache aware algorithms, loop unrolling, parallelisation and parameter tuning lead to optimised implementations at a level of 90% peak performance of the floating point pipelines on recent Intel Sandy Bridge and AMD Bulldozer CPU cores, both with AVX vector instructions as well as on Nvidia Fermi GPU architectures.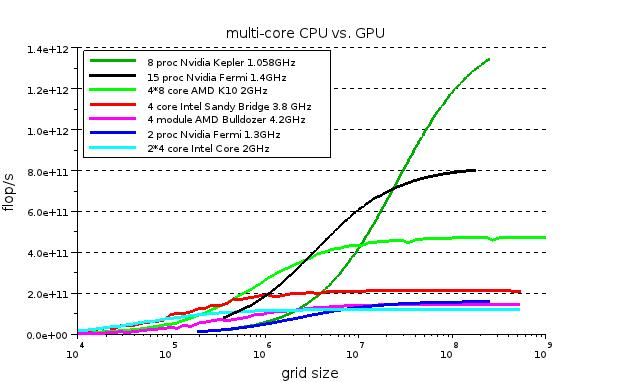
GPU Computing: Numerical Relativity Raytracer
A small project of a real-time parallel raytracer in Nvidia Cuda. Based on an analytic space-time metric of rotating black holes (Kerr metric), each light ray is given as the solution of an ordinary differential equation.

binary system of neutron stars in a box
Cuda source code at Github
Android App GRRay (CPU version) at Google Play
GPU Computing: Shallow Water Equation
A student project of a numerical shallow water simulator with visualisation. Lax-Wendroff scheme on a staggered grid. Real-time simulation and visualisation with Nvidia Cuda and OpenGL.

water waves around some islands

breaking dam
wave simulator presentation at PHSP11 by Martin Pfeiffer
wave simulator code repository
Several ways of tuning a model problem finite difference stencil computation are discussed. The combination of vectorisation and an interleaved data layout, cache aware algorithms, loop unrolling, parallelisation and parameter tuning lead to optimised implementations at a level of 90% peak performance of the floating point pipelines on recent Intel Sandy Bridge and AMD Bulldozer CPU cores, both with AVX vector instructions as well as on Nvidia Fermi GPU architectures.
| [1] | G. Zumbusch. Tuning a finite difference stencil. Poster, GPU Technology Conference 2012 (GTC), San Jose, CA, 2012. [ bib | .pdf ] |
| [2] | G. Zumbusch. Tuning a finite difference computation for parallel vector processors. In M. Bader, H.-J. Bungartz, D. Grigoras, M. Mehl, R.-P. Mundani, and R. Potolea, editors, 2012 11th International Symposium on Parallel and Distributed Computing, CPS, pages 63-70. IEEE Press, 2012. DOI 10.1109/ISPDC.2012.17. [ bib | .pdf ] |
| [3] | G. Zumbusch. Vectorized higher order finite difference kernels. In P. Manninen and P. Öster, editors, PARA 2012, State-of-the-Art in Scientific and Parallel Computing, volume 7782 of LNCS, pages 343-357, Heidelberg, 2013. Springer. [ bib | .ps.gz | .pdf | Abstract ] |
| [4] | G. Zumbusch. Breaking the Memory Barrier for Finite Difference Algorithms. Session S3096, GTC 2013, San Jose (CA). video |
A small project of a real-time parallel raytracer in Nvidia Cuda. Based on an analytic space-time metric of rotating black holes (Kerr metric), each light ray is given as the solution of an ordinary differential equation.
binary system of neutron stars in a box
Cuda source code at Github
Android App GRRay (CPU version) at Google Play
GPU Computing: Shallow Water Equation
A student project of a numerical shallow water simulator with visualisation. Lax-Wendroff scheme on a staggered grid. Real-time simulation and visualisation with Nvidia Cuda and OpenGL.
water waves around some islands
breaking dam
wave simulator presentation at PHSP11 by Martin Pfeiffer
wave simulator code repository